Visitas: 2201


Desde hace un tiempo a esta parte, PowerShell de a poco se ha convertido en un estándar para la automatización de tareas en Windows (principalmente, ya que también Microsoft lo ha disponibilizado en otros sistemas operativos también).
Para los DBAs y los que normalmente trabajan con SQL Server, también ha comenzado la adopción de este lenguaje de scripting y shell de línea de comandos. Pero, debo reconocer que para mí y algunos cuantos colegas no hemos llevado la vanguardia en la implementación PowerShell y a veces nos cuesta abandonar a nuestro querido T-SQL.
Pero lo que me ha motivado a utilizar PowerShell, al menos de mi parte, es para utilizar esta gran herramienta dbatools, desarrollada completamente por la comunidad y para la comunidad en forma libre y sin costo.
Permite realizar cientos (mas de 300) de tareas en forma automatizada, minimizando errores y aplicando las best-practices creadas por cientos de profesionales de SQL Server.
Configurar PowerShell
Para comenzar antes que nada, debemos tener instaladas las versiones más actualizadas, ya que dependiendo del sistema operativo que tengamos instalados, estos poseen diferentes versiones de PowerShell (Fig.1)
| O.S. |
Executable |
Execution Policy |
PowerShell Version |
| 2008 R2 – PowerShell type |
SQLPS.exe |
RemoteSigned |
2.0 |
| 2008 R2 – CmdExec type |
powershell.exe via cmd.exe |
System Configured |
Latest Installed |
| 2012 – PowerShell type |
SQLPS.exe |
RemoteSigned |
2.0 |
| 2012 – CmdExec type |
powershell.exe via cmd.exe |
System Configured |
Latest Installed |
| 2014 – PowerShell type |
SQLPS.exe |
RemoteSigned |
4.0 |
| 2014 – CmdExec type |
powershell.exe via cmd.exe |
System Configured |
Latest Installed |
| 2016 – PowerShell type |
SQLPS.exe |
RemoteSigned |
4.0 |
| 2016 – CmdExec type |
powershell.exe via cmd.exe |
System Configured |
Latest Installed |
FIG. 1. Fuente – Derik Hammer: https://www.sqlhammer.com/running-powershell-in-a-sql-agent-job/
Para obtener la actualización de Powershell podemos ir directamente a la descarga desde Microsoft:
Ref. https://docs.microsoft.com/en-us/powershell/scripting/setup/installing-windows-powershell?view=powershell-6#upgrading-existing-windows-powershell
Configurar el Execution Policy
Otro punto importante es la Política de Ejecución (Execution Policy), que también dependiendo de la versión cambia su configuración.
Según la teoría, la Política de Ejecución se encuentra por razones de precaución y no seguridad. Es decir que intencionalmente se puede modificar el Scope de aplicación según la necesidad del script a correr. Y la función principal es prevenir la ejecución de código no seguro, aunque no es una política activa de Seguridad que proactivamente puede detener una ejecución.
Ref: https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.core/about/about_execution_policies?view=powershell-6
Y precisamente para ejecutar las funciones de dbatools minimamente requiere que esta opción se encuentre en “Remote Signed”, es decir que se podrán ejecutar Scripts que no están alojados en la computadora local deben estar firmados digitalmente para ser ejecutados.
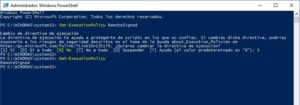
Desde una ventana PowerShell con permisos elevados de Administrador, se puede ver el ExecutionPolicy y cambiarlo:
Código: Set-ExecutionPolicy RemoteSigned
Instalación de dbatools
Luego de actualizar PowerShell y configurar la Execution Policy, tenemos que instalar el modulo de dbatools.
Esto se puede realizar en forma offline, sino se dispone una conexión a internet y se puede realizar siguiendo los pasos muy bien descriptos del sitio de dbatools: https://dbatools.io/offline/
Básicamente se descarga el módulo, ya sea desde la Galería de PowerShell oficial de Microsoft, o desde el sitio oficial de dbatools, se descomprimen los scripts y luego se ejecuta localmente la instalación.
Y la otra opción (y más directa) si se dispone de una conexión a internet, es utilizando desde la linea de comandos de PowerShell ejecutando el comando “Install-Module dbatools”
Aunque previamente hay que ejecutar unos comandos adicionales para confiar en el repositorio y luego importar los módulos instalados.
El paso a paso se puede ver : https://dbatools.io/soup2nutz/
Y en el tutorial de YouTube: installing modules from the powershell gallery
Con esto completo ya tendremos en nuestro servidor o equipo, las herramientas instaladas y podremos ejecutar todos los comandos para automatizar las tareas como Backups y Restores entre diferentes ambientes, o realizar migraciones completas de todas las bases de datos desde un server a otro, y tantas otras más como la lista a continuación:
https://dbatools.io/functions/
Los invito a probarla y porque no a colaborar en esta gran herramienta abierta para la comunidad.
En el próximo post, vamos a ver como programar tareas automatizadas de dbatools y PowerShell desde SQL Server Agent.
Agradecimientos y Referencias
Equipo de dbatools : https://dbatools.io/
Blog de Derik Hammer: https://www.sqlhammer.com/running-powershell-in-a-sql-agent-job/








 19/03/2018
19/03/2018 09:00 hs
09:00 hs Sheraton Libertador. Av. Córdoba 690, CABA
Sheraton Libertador. Av. Córdoba 690, CABA
