
Visitas: 992
Vamos a comenzar con esta serie de posts dedicados a esta tecnología que brinda Microsoft hace ya un tiempo y cobra mucho valor en estas épocas de volúmenes masivos de información.
Azure SQL Datawarehouse es un servicio Cloud de Microsoft Azure, que ofrece una base de datos relacional con procesamiento paralelo masivo (MPP) capaz de procesar volúmenes masivos de datos.
Bien, hasta ahí la definición de diccionario para este componente de la familia de SQL Server de Microsoft. Pero para entender a este hermano mayor de SQL Server, tendremos que hacer un mínimo de historia y repaso de la arquitectura de Procesamiento Paralelo Masivo (MPP) y como esta difiere con la arquitectura tradicional de SQL Server (SMP o Symmetric Multi-Processing ).
Arquitectura de Procesamiento MPP y SMP
Vamos las definiciones de ambas arquitecturas y como se componen.
SMP: Symmetric Multi-Processing, es un sistema multi-procesador con un alto nivel de acoplamiento donde cada procesador comparte los recursos. Estos recursos son un único Sistema Operativo (OS), Memoria, Dispositivos de I/O e interconectados en un BUS común.
Dicho de una manera simple y sencilla, se trata de un servidor de arquitectura tradicional que conocemos normalmente en las implementaciones de SQL Server.
Fig. 1 Arquitectura SMP

MPP: Massively Parallel Processing , es el procesamiento coordinado de una única tarea realizara por múltiples procesadores, que utilizan sus propio Sistema Operativo y Memoria y que se comunica con cada otro utilizando una interfaz de mensajería. Esta arquitectura se puede implementar con un sub-sistema de disco de tipo shared-nothing (discos locales) o shared-disk (discos en un arreglo, SAN, NAS, etc.)
En la arquitectura Shared-Nothing, no existe ningún punto de contención en el sistema completo y los nodos no comparten recursos de memoria o almacenamiento, Los datos son particionados horizontalmente por cada nodo, para que cada uno de éstos tenga un sub-set de filas de cada tabla almacenada en la base de datos. De esta forma cada nodo procesará solo la porción de registros que posee en sus discos. Los sistemas basados en esta arquitectura pueden escalar en forma masiva ya que no poseen un un punto “cuello de botella” que pueda afectar la performance de todo el sistema.
Fig. 2 Arquitectura MPP shared-nothing

SQL Data Warehouse Componentes y Características
Bien, ahora que ya repasamos la arquitectura MPP, podemos decir que SQL Data Warehouse es un sistema de base de datos distribuido de Procesamiento Paralelo Masivo (MPP, definición larga y de diccionario :-))
Por debajo del capot, el motor de SQL Data Warehouse distribuye los datos en muchas unidades de procesamiento y un almacenamiento shared-nothing (claro que siempre con un criterio! Y tratando de que se haga lo más parejo posible, salvo que nosotros le indiquemos otra cosa, que ya veremos más adelante).
Los datos se almacenan en forma redundante en una capa de Storage de tipo Premium (recordemos que es un servicio de Azure) que a su vez se vincula dinámicamente con los nodos de computo que ejecutan las consultas.
SQL Data Warehouse trabaja bajo el concepto de “división y conquista” para ejecutar cargas de trabajo y querys complejos. Los requerimientos son recibidos por un solo nodo llamado Control Node, el cual optimiza y prepara la distribución del trabajo, para luego enviarlos a los otros servidores que se llaman Compute Nodes, los cuales trabajan en paralelo.
Debido a la arquitectura desacoplada de Almacenamiento y Cómputo, y al ser un servicio de Azure, SQL Datawarehouse puede cumplir con los siguientes:
- Aumentar o reducir el tamaño del almacenamiento en forma independiente a los recursos de cómputo
- Aumentar o reducir la capacidad del cómputo sin mover datos
- Pausar la capacidad de cómputo dejando intactos los datos, y en consecuencia solo pagar por el almacenamiento
- Reactivar la capacidad de cómputo durante las horas de operación del negocio
Fig. 3 SQL Datawarehouse detalles de componentes
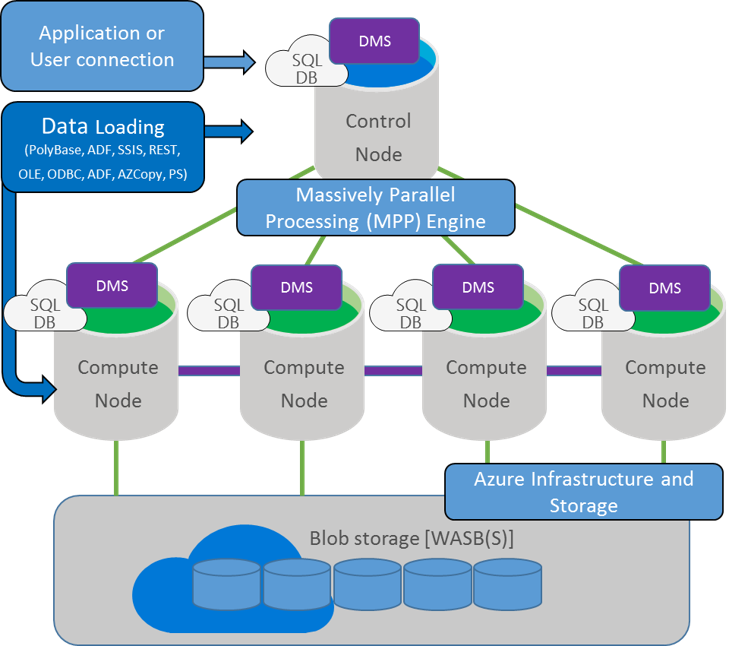
Control node: El Control node administra y es el encargado de optimizar los querys. Es la capa de presentación que interactúa con todas las aplicaciones y conexiones. En un SQL Data Warehouse, el Control node internamente no es otra cosa que una instancia de Azure SQL Database, y una vez que nos conectamos a él se puede ver que es lo mismo que una conexión a SQL Server tradicional. La diferencia es que el Control node coordina todo el movimiento de datos y el procesamiento requerido para ejecutar los querys en forma paralela sobre los datos distribuidos. Cuando se envía un query T-SQL a ejecutar, el Control node lo transforma en querys separados para que puedan ejecutarse en paralelo en cada Compute Node.
Compute nodes: Cada Compute node es el músculo detrás del SQL Data Warehouse. Cada uno de éstos, son instancias Azure SQL Database que almacenan los datos y procesan los querys. Cada vez que se añade información, el SQL Data Warehouse distribuye los registros en cada Compute node que posee la implementación. Estos Compute nodes son los que trabajan en paralelo para ejecutar cada query sobre la porción local de datos que posee cada uno. Luego de procesar, estos le pasan los resultados al Control node. Y para finalizar el Control node realizar las agregaciones de todas las partes para devolver el resultado final.
Storage: Toda la información es almacenada en Azure Blob storage. Cuando los Compute nodes trabajan con los datos, estos escriben y leen directamente desde y hacia al blob storage. Debido a la característica de Azure storage que pude expandirse transparente y ampliamente, , SQL Data Warehouse hereda esta característica. Además, dado que el almacenamiento y el cómputo se encuentran separados, SQL Data Warehouse puede escalar el almacenamiento en forma independiente de escalar los nodos de cómputo y vice-versa (maximizando el costo y eficiencia de uso de la solución). Asimismo, Azure Blob storage es una solución de almacenamiento que es completamente tolerante a fallos, y automatiza el proceso de backup y restore.
Data Movement Service: El servicio de Data Movement (DMS) es el encargado de “mover” los datos entre los nodos. El DMS otoga a los Compute nodes acceso a los datos que necesitan para los joins y las agregaciones . El DMS no es un servicio de Azure, es un servicio de Windows que se ejecuta al lado del servicio de Azure SQL Database en todos los nodos.. El DMS es un proceso background que no puede ser accedido en forma directa. Sin embargo, se pueden ver los query plans y observar las operaciones del DMS, ya que el movimiento de datos es requerido normalmente para ejecutar un query en paralelo.
Resumen
Como hemos podido ver, SQL Datawarehouse es más que una sola caja corriendo un gran SQL Server, es una arquitectura distribuida y con el corazón en el servicio de DMS y el Control Node. Si bien existen ofertas de Hardware de DELL o HP para ejecutar esta arquitectura on-premises, el beneficio completo se ve en el servicio de Azure ya que a diferencia de on-premises se puede escalar y disminuir tanto la capacidad de cómputo como el almacenamiento, y en consecuencia se maximiza la performance y el costo al mismo tiempo.
Y desde mi perspectiva, el punto más importante es que toda la solución utiliza código T-SQL, lo que permite apalancar cualquier solución existente de SQL Server (con algún cambio menor obviamente) y utilizar la potencia de procesamiento en paralelo.
En las próximas series, veremos cómo aprovisionar un entorno de SQL Datawarehouse en Azure y como probar las distintas características del motor.
Links y Referencias
SQL DW: https://azure.microsoft.com/es-es/services/sql-data-warehouse/
Doc. Producto: https://docs.microsoft.com/es-es/azure/sql-data-warehouse/