

Visits: 127
Microsoft Fabric finalmente ha sido anunciado como Public Preview durante Microsoft Build 2023.
Y esencialmente, es una nueva herramienta, o bien una especie de nueva herramienta dentro todo el ecosistema de la plataforma de Datos de Microsoft.

Debido a que el anuncio fue de una magnitud importante, es conveniente separar un poco la visión general de Microsoft sobre el mundo de datos y bajar a tierra cada concepto de esta nueva herramienta.
Lo que nos lleva a tratar de responder algunas preguntas iniciales:
- ¿Qué es Microsoft Fabric?
- ¿Cómo funciona?
- ¿Por qué nos debería importar?
- ¿Realmente todos lo vamos a usar?
- ¿Lo vamos a usar de repente sin darnos cuenta de que realmente lo hemos activado?
- ¿Cómo encaja en el mundo existente?
- ¿Dónde encaja Synapse Analytics?
- ¿Dónde encaja Power BI?
¿Qué es Microsoft Fabric?
Bien, para comenzar tomando la definición oficial de Microsoft, Fabric se define como como “la plataforma de datos en la era de la IA”.
Es una nueva plataforma de tipo SaaS (Software as a Service) que encapsula todos los diferentes tipos de cargas de trabajo y cómputo que había Synapse analytics en una versión “SaaSificada”, sumado a la agradable facilidad de uso que tenemos en Power BI.

Agrega toda la capacidad de un Lake-House más todas las piezas de Synapse Analytics, traídos a la misma plataforma SaaS que Power BI. Eso es lo que proclama ser Microsoft Fabric.
Si ya somos usuarios de la versión premium de Power BI, algunas de estas características se encontrarán habilitadas a partir de este lanzamiento.
En resumen, Fabric es una plataforma SASS que encapsula Power BI más muchos de los componentes de Synapse Analytics y otras nuevas capacidades.
Haciendo un paralelo, la forma en que se definió a Fabric sería como hablar de Microsoft Office, pero para el mundo de datos.
Por lo que asumiendo los costos (y claramente habrá algunos), sería como usar Office 365. Entonces, si tengo que hacer una presentación podemos utilizar PowerPoint, o Word para componer un documento o si tenemos que hacer cálculos utilizaríamos Excel.
Tomando esta idea como concepto, deberíamos pensar en agrupar bajo un mismo portal todas las actividades de datos. Por ejemplo, un Pipeline de Copy en Data Factory o quizás empezar a trabajar directamente desde un Reporte de Power BI con un conjunto de datos, que a su vez otro usuario puede haber trabajado con un Notebook de Python o mediante un Dataflow.
Un único almacenamiento para gobernarlos a todos
Todas estas cargas de trabajo que mencionamos, si bien pertenecen a productos que ya existían y claramente estaban orientadas a diferentes roles de usuario, ahora se encuentran bajo una misma Suite y cuyo soporte de almacenamiento es común a todas a ellas.
Este es un pilar de Fabric, todo el almacenamiento es un único tipo de storage de tipo Lake.
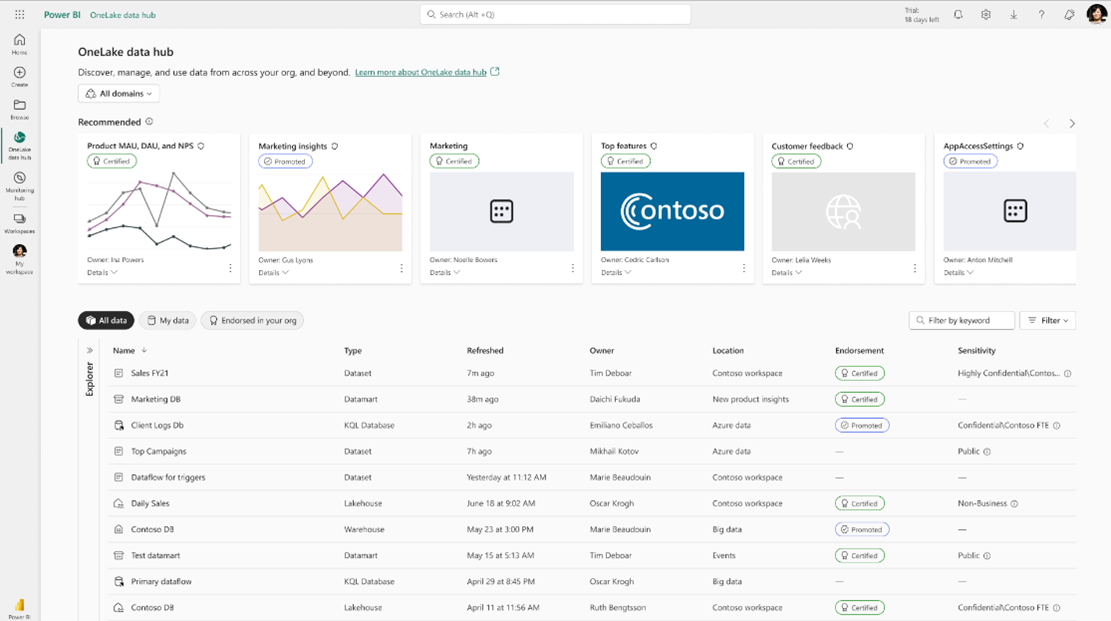
Microsoft ha presentado este concepto de almacenamiento tipo Lake unificado como si fuese el concepto de OneDrive, pero orientado a cargas de datos.
Hoy todos conocemos el servicio de OneDrive, donde hay Teams y también carpetas de Sharepoint. Y siempre tenemos una copia en sincronía local en nuestros equipos, por lo que toda la organización puede trabajar y compartir los archivos que necesitan.
Y esencialmente, Microsoft está tratando de imitar esta funcionalidad con este almacenamiento Lake, basado en Cloud Storage.
Hasta ahora si teníamos que trabajar con diferentes tipos de archivos o fuentes de datos, incluso en diferentes ubicaciones o nubes, la integración de estos silos de datos requería mucha complejidad para poder conectarnos, copiar o masajear la información.
Esta situación terminaba inevitablemente requiriendo tareas de Data Engineering, pipelines de ETL/ELT o simplemente una de-duplicación de estos datos múltiples veces para poder trabajar con ellos.
Pues bien, ahora Fabric con el almacenamiento unificado de tipo Lake, quiere poner fin a estas tareas complejas presentando una “única” copia de los datos con los que todos los usuarios vamos a poder trabajar.
Y este es un gran concepto, ya que teniendo un único punto de donde parten los datos, se simplifica en una gran medida el trabajo con la seguridad, para decidir quién puede acceder a qué datos, y toda la integración con el resto de las herramientas.
Por otro lado también, se ofrecerá una interfaz similar a OneDrive, llamada OneLake donde podremos interactuar con este almacenamiento para subir, modificar u obtener archivos tan fácilmente como conectarnos con nuestras credenciales incluso desde un desktop.
Un motor para cada tarea
La evolución de las diferentes cargas de trabajo, hacen que un único motor de procesamiento no sea suficiente.
Y es por esto que MS Fabric, nos permite utilizar el poder de los diferentes tipos de motores bajo una misma interfaz y sin tener que preocuparnos de aprovisionar o configurar previamente una capacidad de cómputo específica.

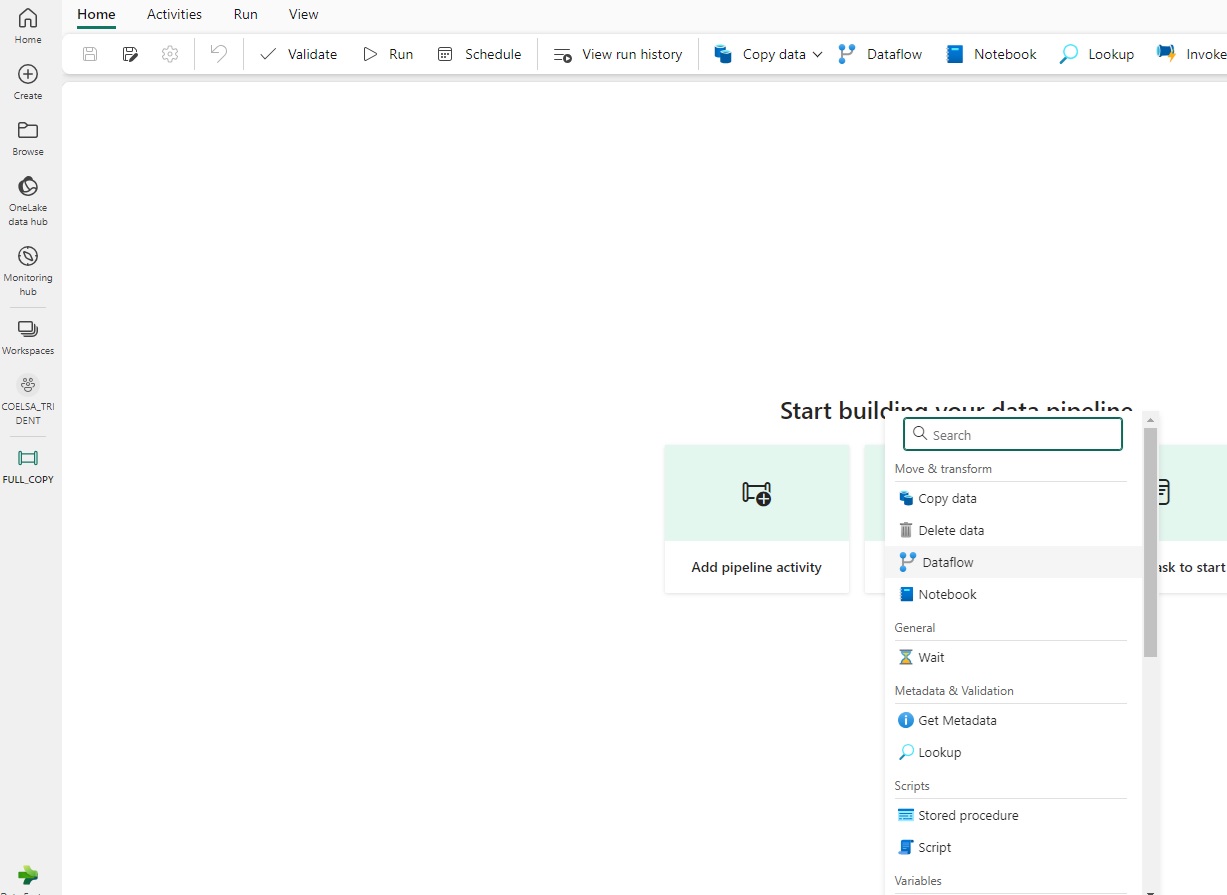
Data Factory
En Fabric nos encontramos con una “evolución” de los pipelines y Mapping Dataflows de Synapse Analytics, que ahora utiliza Power Query para copia y transformación de flujos de datos.
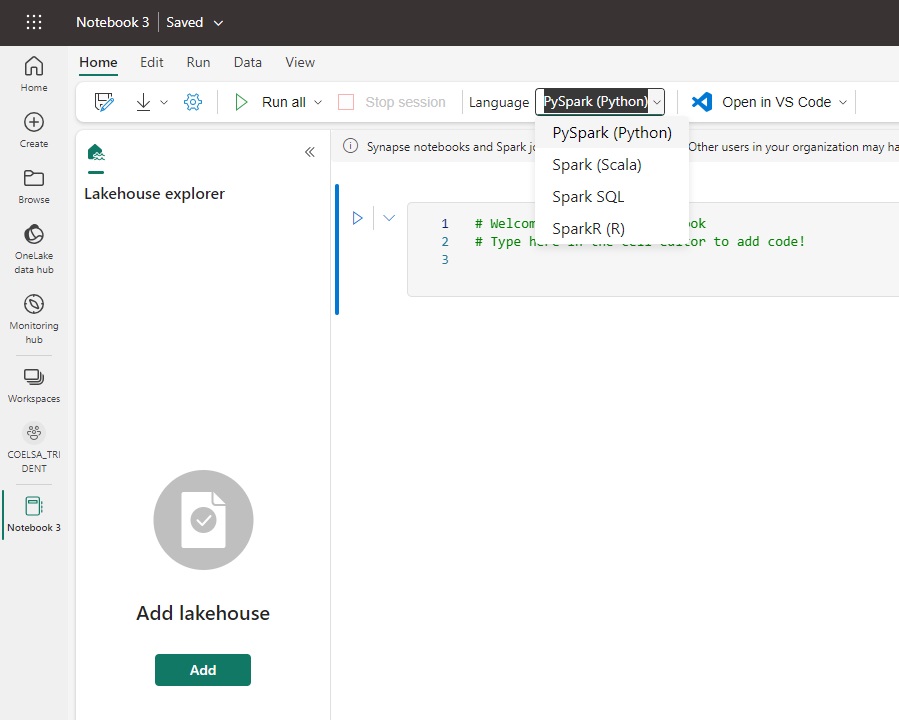
Data Engineering
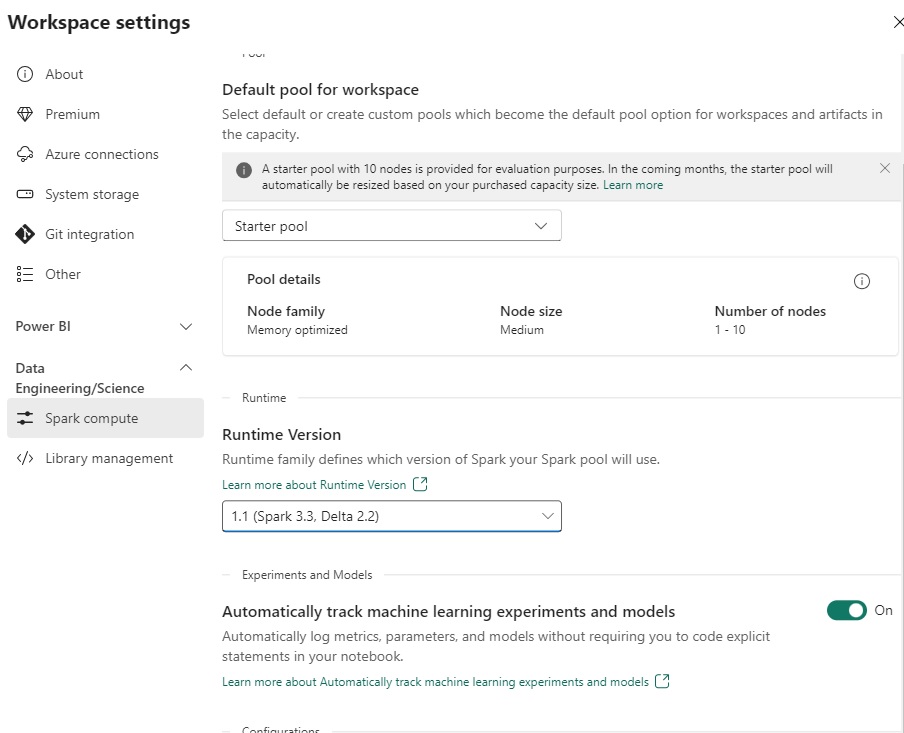
En cuanto a ingeniería de datos, esencialmente nos encontramos con el motor de Spark que teníamos en Synapse, donde vemos la versión 1.1 que incluye Spark 3.3 y Delta 2.2 y se espera que el ritmo de actualización sea más constante y con una experiencia más continua y que sea completamente transparente con el resto de las piezas de Fabric.
Data Science
Por el lado de Ciencia de Datos, tenemos la capacidad de crear Modelos y Experimientos y luego incluir éstos dentro de un Pipeline con Spark Jobs.
Data Warehousing
Luego llegamos al componente de Data Warehousing, el mundo un poco más conocido para los que trabajamos con T-SQL.
En este motor, tenemos la capacidad de escribir SQL y ejecutar Stored Procedures con cargas de trabajo transaccionales.
Lo que realmente estamos viendo con Fabric es que no vamos a tener que elegir si trabajar con un SQL Pool dedicado y un SQL Pool Serverless. Ahora vamos a tener un único motor SQL que operará con un único almacenamiento de datos que ya se encuentra previamente configurado.
Es quiere decir que todo el almacenamiento de nuestras tablas y registros se encontrará dentro del OneLake y nuevamente con formato Delta.
Real Time Analytics
Este motor de análisis en tiempo real, toma la forma de lo que teníamos en Azure Data Explorer con lenguaje Kusto, para realizar ingesta y consulta de eventos en tiempo real. Este motor permite trabajar y analizar grandes volúmenes de registros en formato de series temporales, que pueden desde luego ser conectados a Power BI.
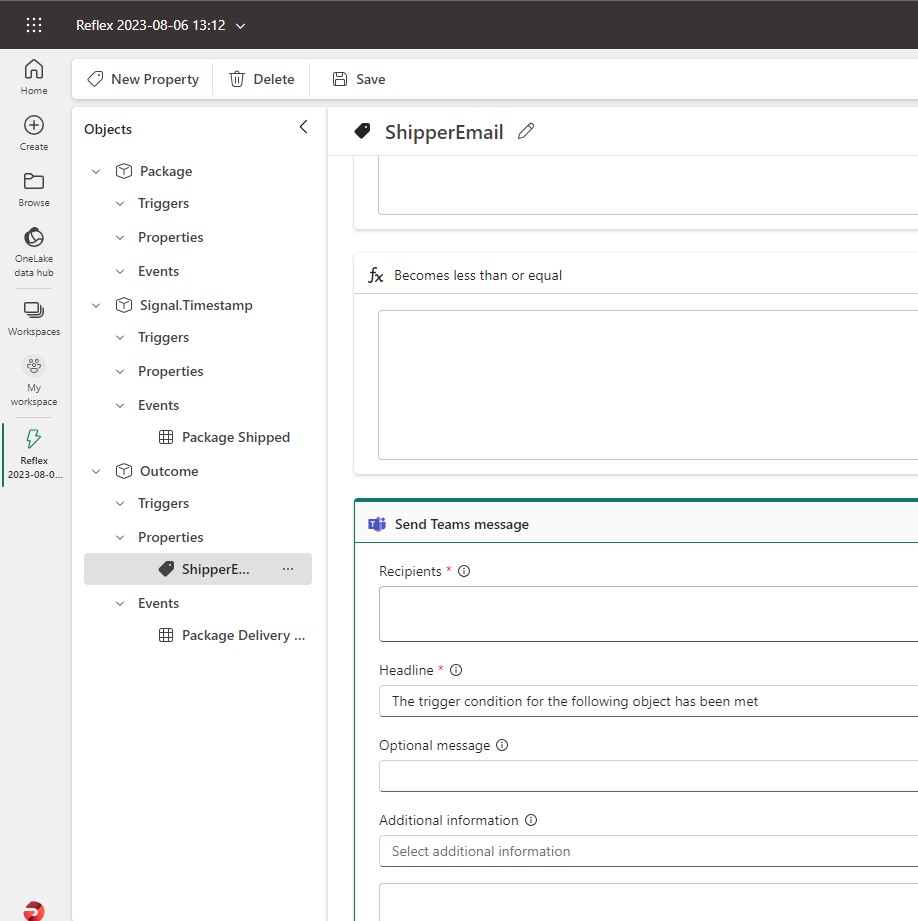
Data Activator
Este motor quizás sea la pieza de Fabric mas novedosa y permite tomar acciones automáticamente basadas en los datos.
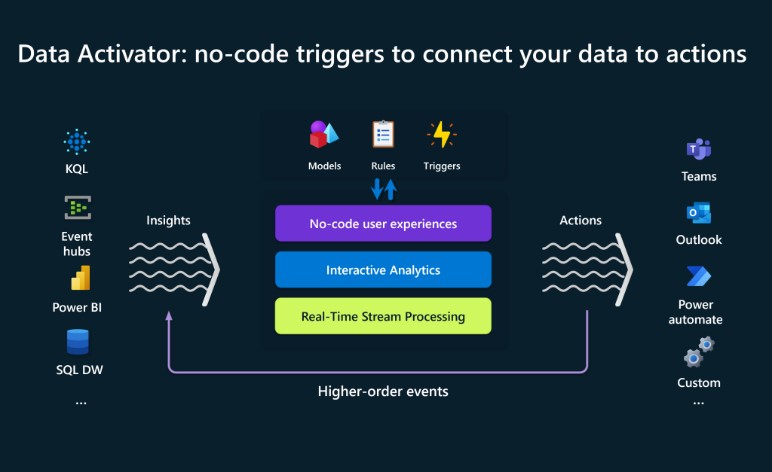
Normalmente para automatizar acciones sobre los datos, se require el desarrollo de código y esto suele ser costoso en tiempo y recursos. Es por esto Fabric ofrece dentro de sus motores a Data Activator con una experiencia “No-Code” para poder tomar acciones directamente desde los datos y sus cambios.
Basado en modelos de datos, reglas de negocio y Triggers que se pueden configurar en forma visual, se crean acciones que pueden desencadenar procesos, alertas y llamadas a otras aplicaciones. Desde un simple email hasta interactuar con Power Automate para crear flujos mas complejos.
Conclusión
Microsoft ha fijado con Fabric una dirección unificada de dónde visualiza sus servicios en términos de datos y análisis en la nube.
Y esto parece ser algo serio, ya que de alguna manera Fabric parece ser el punto de convergencia de las múltiples iniciativas y servicios que existían en el ecosistema de Azure y On Premises de los productos de Microsoft hasta hoy.
Es verdad que aún falta mucho camino y en toda unificación habrá cosas que se perderán y otras se ganarán. Cada pieza de Fabric aún está en desarrollo y otras que aún no han sido anunciadas pero lo importante es que finalmente tenemos una dirección que permite tener una historia consistente de punta a punta con los datos.





