El proximo 27 de Mayo vamos a estar presentes con SQLArgentina en el evento de Microsoft dando una jornada completa de sesiones con los mejores speakers.
¡Potenciá tu infraestructura de datos y llevala al siguiente nivel!
Los datos y la información son los activos más valiosos en la era de la Transformación Digital.
Te invitamos a una jornada pensada para ayudar a DBAs y líderes de IT a potenciar su infraestructura, mantener sus datos seguros, aumentar la velocidad de sus implementaciones y trabajar de forma más ágil y rápida.
Aprendé más sobre la Plataforma de Datos de Microsoft, con los principales referentes técnicos del país.
TEMÁTICAS A ABORDAR:
Fin de soporte extendido SQL Server 2008 y 2008 R2
Modernización de plataforma de datos.
Power BI (Dataflows, Report Server).
Corriendo SQL Server en Docker Containers.
Analysis Services
Powershell
Azure Cloud (Azure Datawarehouse, Azure SQL DB, IaaS VMs, Machine Learning, Big Data Clusters)
Técnicas de Performance.
Lo invitamos el día Lunes
27 de mayo de 09:00 a 18:00 hs
Microsoft Buenos
Aires: Bouchard 710 – 4° piso, Capital Federal
RSVP a través de este link.
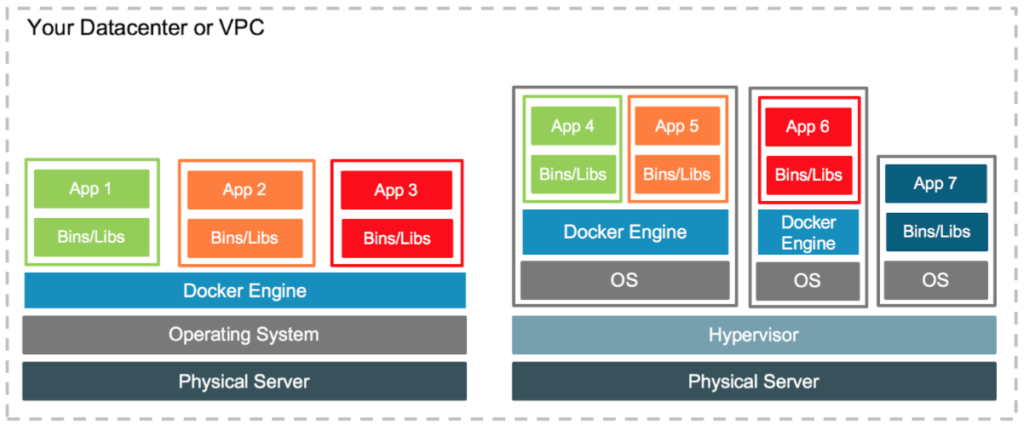
Un Contenedor es fundamentalmente una manera de
empaquetar el software para que una aplicación pueda ser ejecutada, incluyendo
los binarios y sus dependencias pero haciendo a esta independiente de la
arquitectura subyacente.
Todo código, bibliotecas y dependencias de la
aplicación se agrupan en un paquete como como un artefacto inmutable. Es decir, que cuando una aplicación es
empaquetada en un Contenedor , sabremos exactamente cómo se ejecutará de manera
predecible, repetible e inmutable. No encontraremos ningún error inesperado al
moverlo a una nueva máquina, o entre entornos.
Un Contenedor puede ser pensado como ejecutar una
máquina virtual, pero sin todo el overhead de tener que levantar todo un
sistema operativo. Por esta razón, empaquetar una aplicación en un contenedor
frente a instanciar una máquina virtual mejorará el tiempo total de encendido
significativamente y reducirá el footprint total de consumo de recursos.
Las características anteriores hacen a los Contenedores una gran herramienta y un bloque de construcción esencial en una arquitectura de la nube moderna o de microservicios.
Los contenedores
originalmente construidos sobre instrucciones de Kernel Linux, se volvieron
disponibles sobre Windows a partir Windows Server 2016.
El objetivo
principal de usar contenedores fue y es actualmente poder ejecutar las
aplicaciones en un entorno de servidor de la misma manera que lo realiza en un
entorno de desarrollo, evitando los cambios de arquitectura y dependencias.
Ahora bien, a esta
excelente idea le faltaba un componente esencial para poder ser utilizada. De
qué manera los usuarios pueden interactuar con esta tecnología? Esto incluye la
administración, la orquestación y la seguridad para los contenedores. La respuesta
lleva a otro componente de software, como Docker (ampliamente utilizado),
Kubernetes, y otros más específicos en Cloud como Azure Container Server
(AKS).
Una
vez instalado el software, como primer paso, se crea un archivo especial
llamado “Dockerfile”. Los archivos “Dockerfile”
definen un proceso de construcción, el cual una vez utilizado con el comando
‘docker build’ , se produce una “imagen docker”
inmutable.
Este proceso sería como pensar en un “Snapshot” de la aplicación, que
se prepara para ser instanciada en cualquier momento.
Para iniciar esta imagen, se ejecuta el comando
‘docker run’ en cualquier ambiente donde se encuentre corriendo el proceso de
docker. Este puede correr tanto en un desktop como en un servidor de producción
o en la Nube. Sin importar donde se ejecute la imagen, esta correrá de la misma
forma siempre.
Adicionalmente Docker provee un
repositorio en la Nube, llamado Docker Hub. Podríamos pensar en esto como si fuera GitHub para imágenes
Docker. De esta forma se puede utilizar Docker Hub para almacenar y distribuir
las imágenes de los contenedores que uno construya.
Bien, hasta este
punto hicimos una introducción a Containers y Docker, pero… Que somos? Somos
Base de datos!
Entonces, veamos un
ejemplo para descargar una imagen de SQL Server 2017 sobre Linux ya
contenerizada sobre Docker, desde el repositorio oficial de Micosoft.
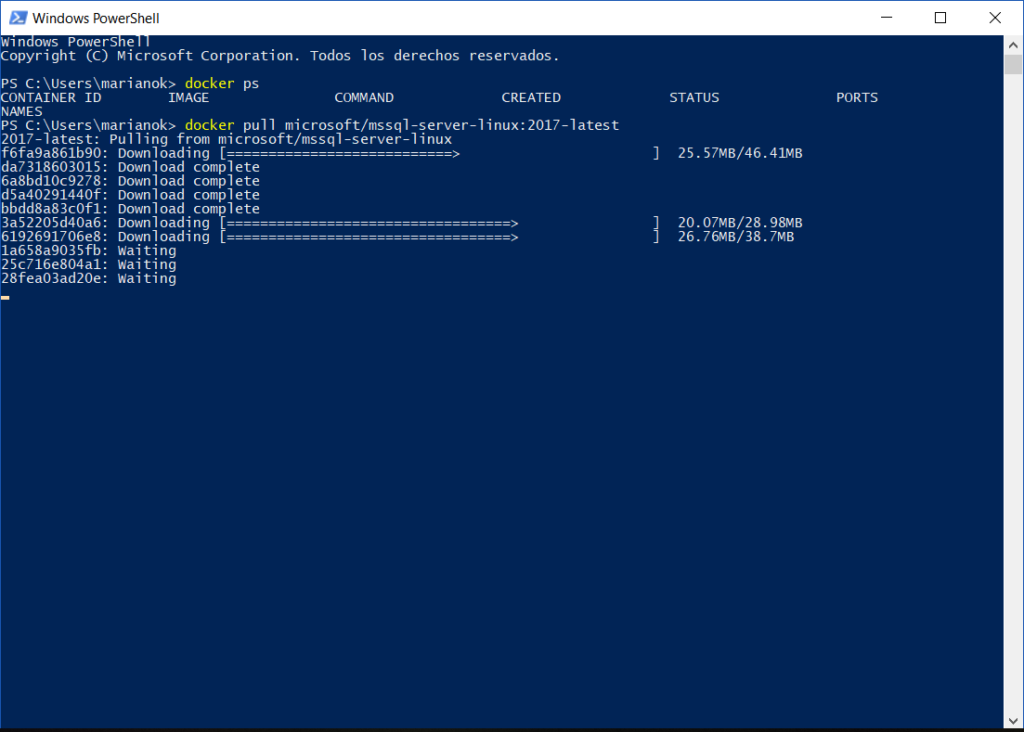
Docker Pull – Descargando la imagen
Desde la linea de
comandos, realizaremos un Pull de la imagen de SQL Server 2017 para Linux la
cual es completamente compatible para ser ejecutada en containers. Este proceso
es realmente rápido pensando en que estamos bajando una imagen funcional de SQL
Server.
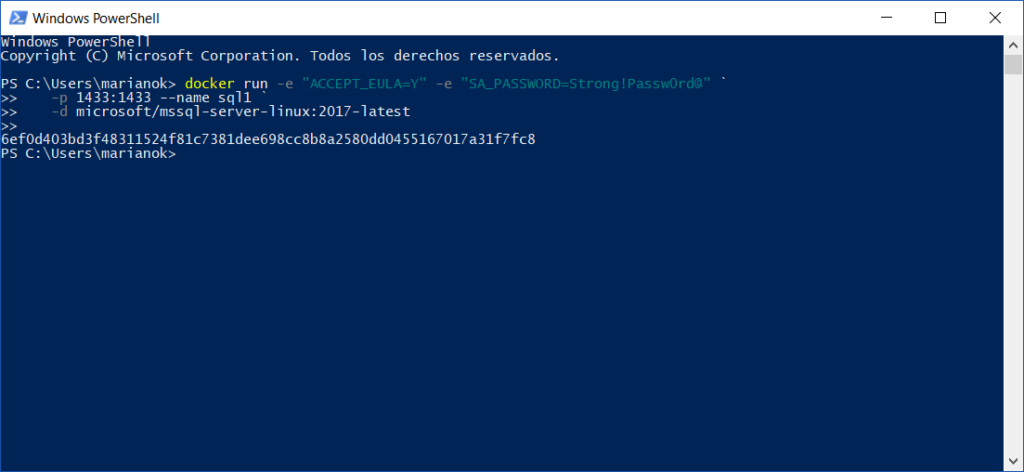
Una vez finalizado
el proceso de Pull, solo resta instanciar la imagen. En el caso de SQL Server
se deben configurar los parámetros de Aceptación de Contrato de Usuario Final,
establecer la Contraseña del SysAdmin, el puerto TCP para conectarnos y el nombre
de la instancia docker.
Inmediatamente
tendremos nuestro contenedor ejecutando un SQL Server 2017 completo y listo
para conectarnos y trabajar.
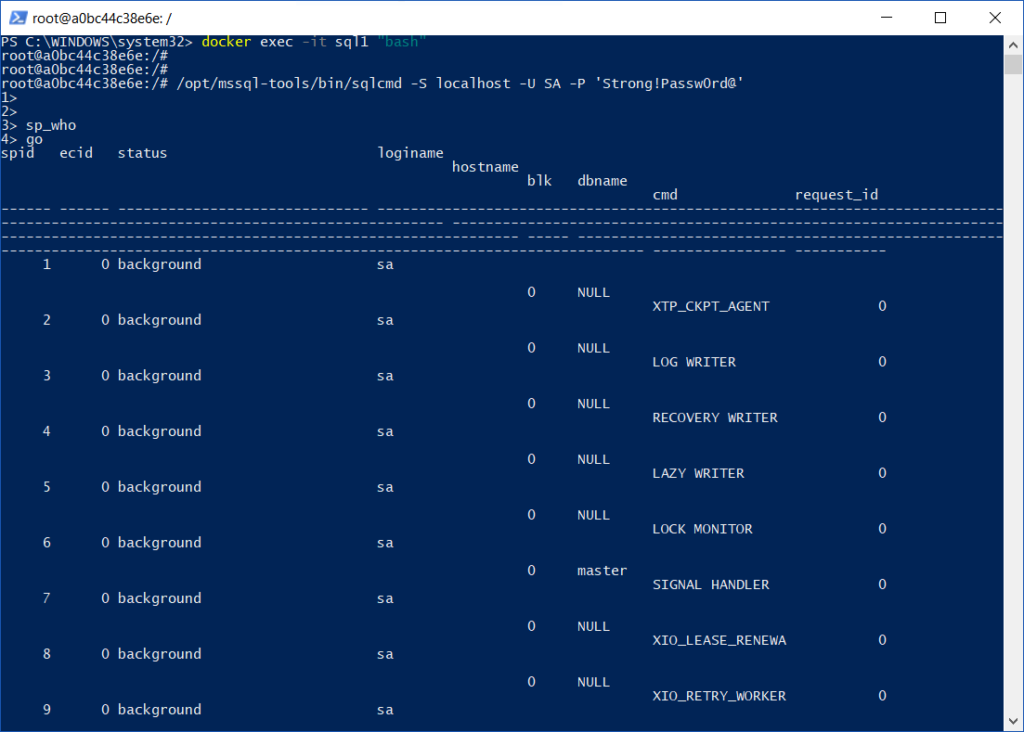
Conectándonos a la Instancia
Podemos conectarnos
directamente desde la misma línea de comandos, invocando un shell de Linux
sobre nuestro container:
docker exec -it sql1 "bash"
Y luego, una vez dentro de la instancia, podemos utilizar el viejo y querido SQLCMD
/opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'Strong!Passw0rd@'
Todo esto en cuestión de escasos minutos y pudiendo realizar todos los pasos en una forma completamente programática. En definitiva un proceso completamente definible como DEVOps.
En próximos posts, veremos cómo avanzar en la configuración y la orquestación de estas nuevas tecnologías.
Presentación sobre el feature de Contained Databases, donde repasamos sus características y cómo podemos utilizarlo en entornos productivos.
Adicionalmente a la posibilidad que brinda de segmentar la seguridad de los usuarios, también nos permite trabajar con múltiples Collations para cada Base de Datos auto-contenida. Esto aumenta la capacidad de una instancia para consolidar más bases de datos independientemente del collation utilizado.
En esta guía describiremos paso a paso como instalar y ejecuta las herramientas de MAP Toolkit y Data Migration Assistant para realizar un relevamiento y evaluar las instancias de SQL Server en situación de Upgrade.