
Visitas: 272
Ya tenemos agenda completa y casi los últimos cupos para este gran evento de Mayo en las oficinas de Microsoft Argentina.

Nos vemos el 27!
RSVP : https://www.microsoftevents.com/profile/form/index.cfm?PKformID=0x6624731abcd
Visitas: 272
Ya tenemos agenda completa y casi los últimos cupos para este gran evento de Mayo en las oficinas de Microsoft Argentina.
Nos vemos el 27!
RSVP : https://www.microsoftevents.com/profile/form/index.cfm?PKformID=0x6624731abcd
Visitas: 458
El proximo 27 de Mayo vamos a estar presentes con SQLArgentina en el evento de Microsoft dando una jornada completa de sesiones con los mejores speakers.

¡Potenciá tu infraestructura de datos y llevala al siguiente nivel!
Los datos y la información son los activos más valiosos en la era de la Transformación Digital.
Te invitamos a una jornada pensada para ayudar a DBAs y líderes de IT a potenciar su infraestructura, mantener sus datos seguros, aumentar la velocidad de sus implementaciones y trabajar de forma más ágil y rápida.
Aprendé más sobre la Plataforma de Datos de Microsoft, con los principales referentes técnicos del país.
TEMÁTICAS A ABORDAR:
| Lo invitamos el día Lunes 27 de mayo de 09:00 a 18:00 hs Microsoft Buenos Aires: Bouchard 710 – 4° piso, Capital Federal RSVP a través de este link. |
Los esperamos!
Visitas: 919
Containers – Que y para qué?
Un Contenedor es fundamentalmente una manera de empaquetar el software para que una aplicación pueda ser ejecutada, incluyendo los binarios y sus dependencias pero haciendo a esta independiente de la arquitectura subyacente.
Todo código, bibliotecas y dependencias de la aplicación se agrupan en un paquete como como un artefacto inmutable. Es decir, que cuando una aplicación es empaquetada en un Contenedor , sabremos exactamente cómo se ejecutará de manera predecible, repetible e inmutable. No encontraremos ningún error inesperado al moverlo a una nueva máquina, o entre entornos.
Un Contenedor puede ser pensado como ejecutar una máquina virtual, pero sin todo el overhead de tener que levantar todo un sistema operativo. Por esta razón, empaquetar una aplicación en un contenedor frente a instanciar una máquina virtual mejorará el tiempo total de encendido significativamente y reducirá el footprint total de consumo de recursos.
Las características anteriores hacen a los Contenedores una gran herramienta y un bloque de construcción esencial en una arquitectura de la nube moderna o de microservicios.
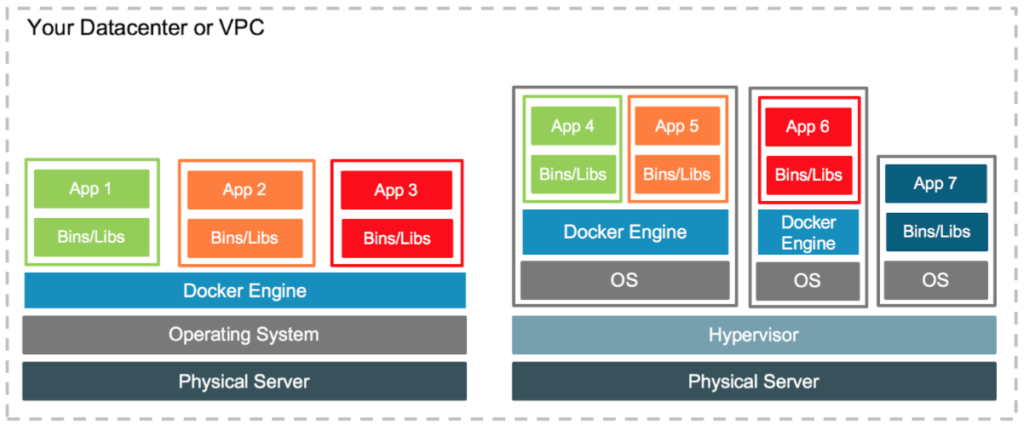
Los contenedores originalmente construidos sobre instrucciones de Kernel Linux, se volvieron disponibles sobre Windows a partir Windows Server 2016.
Ref.: https://msdn.microsoft.com/en-us/magazine/mt797649
https://docs.microsoft.com/en-us/virtualization/windowscontainers/about/
El objetivo principal de usar contenedores fue y es actualmente poder ejecutar las aplicaciones en un entorno de servidor de la misma manera que lo realiza en un entorno de desarrollo, evitando los cambios de arquitectura y dependencias.
Ahora bien, a esta excelente idea le faltaba un componente esencial para poder ser utilizada. De qué manera los usuarios pueden interactuar con esta tecnología? Esto incluye la administración, la orquestación y la seguridad para los contenedores. La respuesta lleva a otro componente de software, como Docker (ampliamente utilizado), Kubernetes, y otros más específicos en Cloud como Azure Container Server (AKS).
https://docs.microsoft.com/en-us/azure/aks/
Construcción y Deploy de Containers con Docker
Docker es un software de código abierto, que provee un amplio set de herramientas para construir e implementar software en contenedores.
Para descargar la versión Destkop (para Windows o Mac) : https://www.docker.com/get-started
Una vez instalado el software, como primer paso, se crea un archivo especial llamado “Dockerfile”. Los archivos “Dockerfile” definen un proceso de construcción, el cual una vez utilizado con el comando ‘docker build’ , se produce una “imagen docker” inmutable. Este proceso sería como pensar en un “Snapshot” de la aplicación, que se prepara para ser instanciada en cualquier momento.
Para iniciar esta imagen, se ejecuta el comando ‘docker run’ en cualquier ambiente donde se encuentre corriendo el proceso de docker. Este puede correr tanto en un desktop como en un servidor de producción o en la Nube. Sin importar donde se ejecute la imagen, esta correrá de la misma forma siempre.
Adicionalmente Docker provee un repositorio en la Nube, llamado Docker Hub. Podríamos pensar en esto como si fuera GitHub para imágenes Docker. De esta forma se puede utilizar Docker Hub para almacenar y distribuir las imágenes de los contenedores que uno construya.
Bien, hasta este punto hicimos una introducción a Containers y Docker, pero… Que somos? Somos Base de datos!
Entonces, veamos un ejemplo para descargar una imagen de SQL Server 2017 sobre Linux ya contenerizada sobre Docker, desde el repositorio oficial de Micosoft.
Docker Pull – Descargando la imagen
Desde la linea de comandos, realizaremos un Pull de la imagen de SQL Server 2017 para Linux la cual es completamente compatible para ser ejecutada en containers. Este proceso es realmente rápido pensando en que estamos bajando una imagen funcional de SQL Server.
docker pull mcr.microsoft.com/mssql/server:2017-latestdocker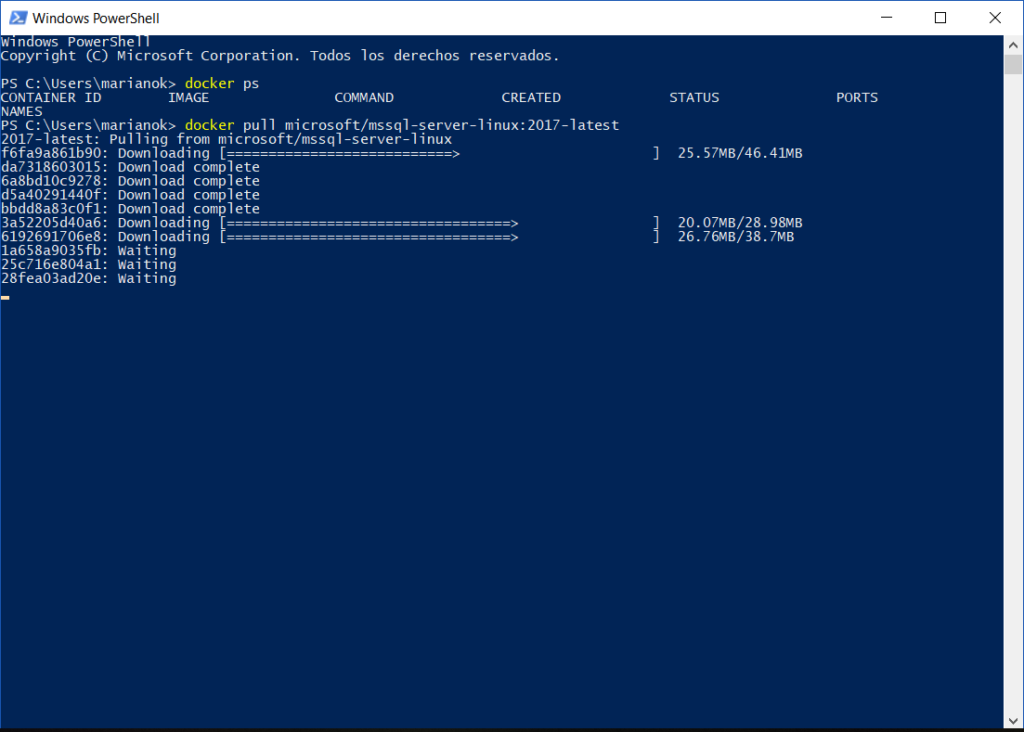
Docker Run – Instanciando la imagen
Una vez finalizado el proceso de Pull, solo resta instanciar la imagen. En el caso de SQL Server se deben configurar los parámetros de Aceptación de Contrato de Usuario Final, establecer la Contraseña del SysAdmin, el puerto TCP para conectarnos y el nombre de la instancia docker.
docker run -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Strong!Passw0rd@" `
-p 1433:1433 --name sql1 `
-d microsoft/mssql-server-linux:2017-latest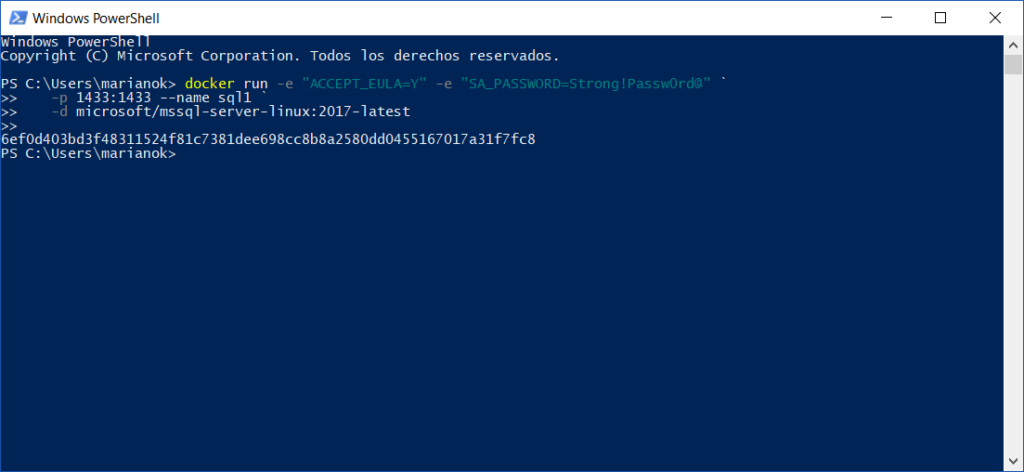
Inmediatamente tendremos nuestro contenedor ejecutando un SQL Server 2017 completo y listo para conectarnos y trabajar.
Conectándonos a la Instancia
Podemos conectarnos directamente desde la misma línea de comandos, invocando un shell de Linux sobre nuestro container:
docker exec -it sql1 "bash"Y luego, una vez dentro de la instancia, podemos utilizar el viejo y querido SQLCMD
/opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'Strong!Passw0rd@'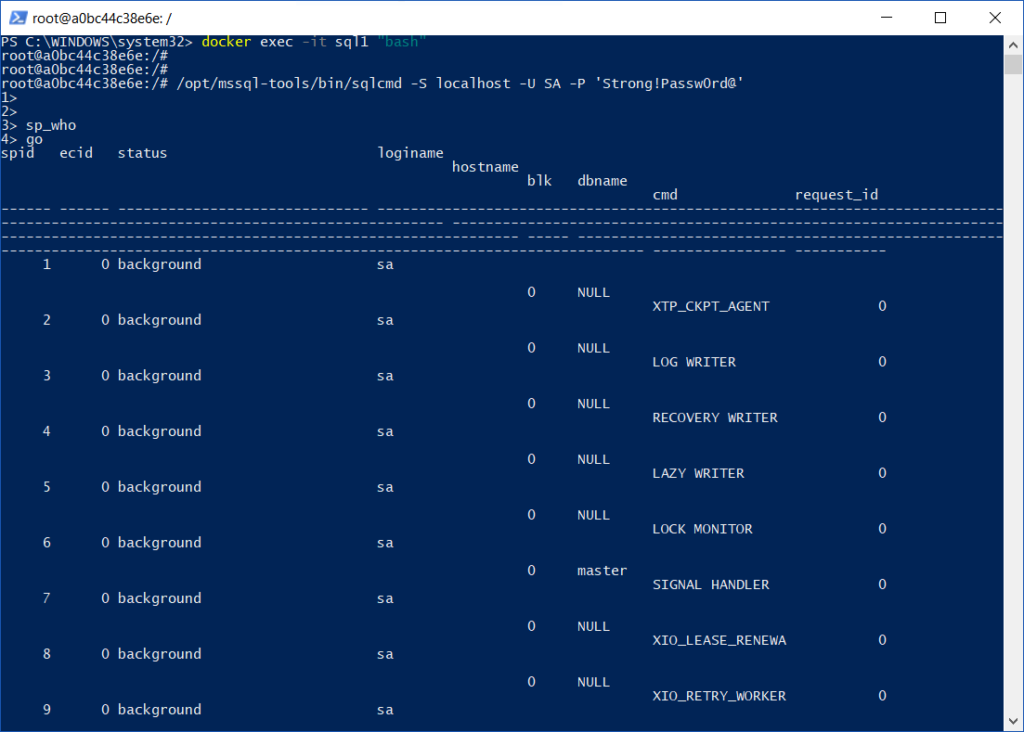
Todo esto en cuestión de escasos minutos y pudiendo realizar todos los pasos en una forma completamente programática. En definitiva un proceso completamente definible como DEVOps.
En próximos posts, veremos cómo avanzar en la configuración y la orquestación de estas nuevas tecnologías.
Visitas: 972
Vamos a comenzar con esta serie de posts dedicados a esta tecnología que brinda Microsoft hace ya un tiempo y cobra mucho valor en estas épocas de volúmenes masivos de información.
Azure SQL Datawarehouse es un servicio Cloud de Microsoft Azure, que ofrece una base de datos relacional con procesamiento paralelo masivo (MPP) capaz de procesar volúmenes masivos de datos.
Bien, hasta ahí la definición de diccionario para este componente de la familia de SQL Server de Microsoft. Pero para entender a este hermano mayor de SQL Server, tendremos que hacer un mínimo de historia y repaso de la arquitectura de Procesamiento Paralelo Masivo (MPP) y como esta difiere con la arquitectura tradicional de SQL Server (SMP o Symmetric Multi-Processing ).
Vamos las definiciones de ambas arquitecturas y como se componen.
SMP: Symmetric Multi-Processing, es un sistema multi-procesador con un alto nivel de acoplamiento donde cada procesador comparte los recursos. Estos recursos son un único Sistema Operativo (OS), Memoria, Dispositivos de I/O e interconectados en un BUS común.
Dicho de una manera simple y sencilla, se trata de un servidor de arquitectura tradicional que conocemos normalmente en las implementaciones de SQL Server.
Fig. 1 Arquitectura SMP

MPP: Massively Parallel Processing , es el procesamiento coordinado de una única tarea realizara por múltiples procesadores, que utilizan sus propio Sistema Operativo y Memoria y que se comunica con cada otro utilizando una interfaz de mensajería. Esta arquitectura se puede implementar con un sub-sistema de disco de tipo shared-nothing (discos locales) o shared-disk (discos en un arreglo, SAN, NAS, etc.)
En la arquitectura Shared-Nothing, no existe ningún punto de contención en el sistema completo y los nodos no comparten recursos de memoria o almacenamiento, Los datos son particionados horizontalmente por cada nodo, para que cada uno de éstos tenga un sub-set de filas de cada tabla almacenada en la base de datos. De esta forma cada nodo procesará solo la porción de registros que posee en sus discos. Los sistemas basados en esta arquitectura pueden escalar en forma masiva ya que no poseen un un punto “cuello de botella” que pueda afectar la performance de todo el sistema.
Fig. 2 Arquitectura MPP shared-nothing

Bien, ahora que ya repasamos la arquitectura MPP, podemos decir que SQL Data Warehouse es un sistema de base de datos distribuido de Procesamiento Paralelo Masivo (MPP, definición larga y de diccionario :-))
Por debajo del capot, el motor de SQL Data Warehouse distribuye los datos en muchas unidades de procesamiento y un almacenamiento shared-nothing (claro que siempre con un criterio! Y tratando de que se haga lo más parejo posible, salvo que nosotros le indiquemos otra cosa, que ya veremos más adelante).
Los datos se almacenan en forma redundante en una capa de Storage de tipo Premium (recordemos que es un servicio de Azure) que a su vez se vincula dinámicamente con los nodos de computo que ejecutan las consultas.
SQL Data Warehouse trabaja bajo el concepto de “división y conquista” para ejecutar cargas de trabajo y querys complejos. Los requerimientos son recibidos por un solo nodo llamado Control Node, el cual optimiza y prepara la distribución del trabajo, para luego enviarlos a los otros servidores que se llaman Compute Nodes, los cuales trabajan en paralelo.
Debido a la arquitectura desacoplada de Almacenamiento y Cómputo, y al ser un servicio de Azure, SQL Datawarehouse puede cumplir con los siguientes:
Fig. 3 SQL Datawarehouse detalles de componentes
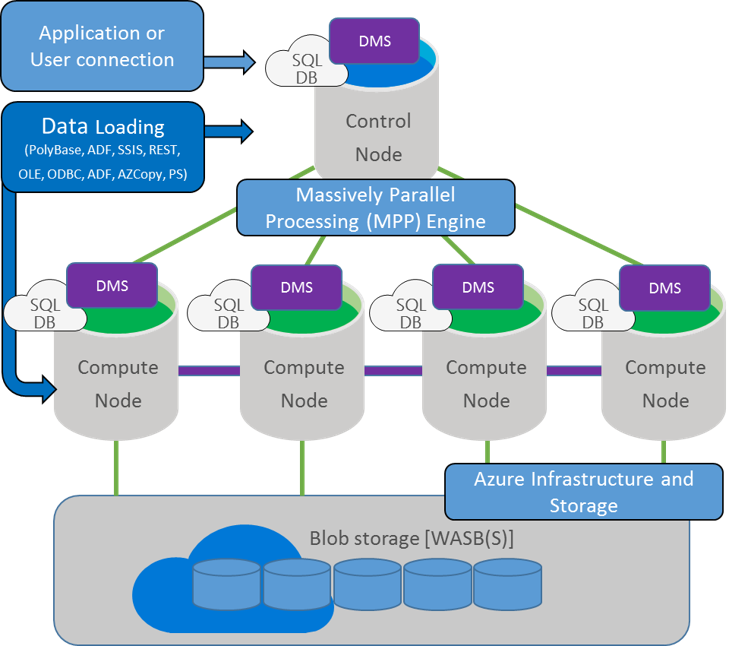
Control node: El Control node administra y es el encargado de optimizar los querys. Es la capa de presentación que interactúa con todas las aplicaciones y conexiones. En un SQL Data Warehouse, el Control node internamente no es otra cosa que una instancia de Azure SQL Database, y una vez que nos conectamos a él se puede ver que es lo mismo que una conexión a SQL Server tradicional. La diferencia es que el Control node coordina todo el movimiento de datos y el procesamiento requerido para ejecutar los querys en forma paralela sobre los datos distribuidos. Cuando se envía un query T-SQL a ejecutar, el Control node lo transforma en querys separados para que puedan ejecutarse en paralelo en cada Compute Node.
Compute nodes: Cada Compute node es el músculo detrás del SQL Data Warehouse. Cada uno de éstos, son instancias Azure SQL Database que almacenan los datos y procesan los querys. Cada vez que se añade información, el SQL Data Warehouse distribuye los registros en cada Compute node que posee la implementación. Estos Compute nodes son los que trabajan en paralelo para ejecutar cada query sobre la porción local de datos que posee cada uno. Luego de procesar, estos le pasan los resultados al Control node. Y para finalizar el Control node realizar las agregaciones de todas las partes para devolver el resultado final.
Storage: Toda la información es almacenada en Azure Blob storage. Cuando los Compute nodes trabajan con los datos, estos escriben y leen directamente desde y hacia al blob storage. Debido a la característica de Azure storage que pude expandirse transparente y ampliamente, , SQL Data Warehouse hereda esta característica. Además, dado que el almacenamiento y el cómputo se encuentran separados, SQL Data Warehouse puede escalar el almacenamiento en forma independiente de escalar los nodos de cómputo y vice-versa (maximizando el costo y eficiencia de uso de la solución). Asimismo, Azure Blob storage es una solución de almacenamiento que es completamente tolerante a fallos, y automatiza el proceso de backup y restore.
Data Movement Service: El servicio de Data Movement (DMS) es el encargado de “mover” los datos entre los nodos. El DMS otoga a los Compute nodes acceso a los datos que necesitan para los joins y las agregaciones . El DMS no es un servicio de Azure, es un servicio de Windows que se ejecuta al lado del servicio de Azure SQL Database en todos los nodos.. El DMS es un proceso background que no puede ser accedido en forma directa. Sin embargo, se pueden ver los query plans y observar las operaciones del DMS, ya que el movimiento de datos es requerido normalmente para ejecutar un query en paralelo.
Como hemos podido ver, SQL Datawarehouse es más que una sola caja corriendo un gran SQL Server, es una arquitectura distribuida y con el corazón en el servicio de DMS y el Control Node. Si bien existen ofertas de Hardware de DELL o HP para ejecutar esta arquitectura on-premises, el beneficio completo se ve en el servicio de Azure ya que a diferencia de on-premises se puede escalar y disminuir tanto la capacidad de cómputo como el almacenamiento, y en consecuencia se maximiza la performance y el costo al mismo tiempo.
Y desde mi perspectiva, el punto más importante es que toda la solución utiliza código T-SQL, lo que permite apalancar cualquier solución existente de SQL Server (con algún cambio menor obviamente) y utilizar la potencia de procesamiento en paralelo.
En las próximas series, veremos cómo aprovisionar un entorno de SQL Datawarehouse en Azure y como probar las distintas características del motor.
SQL DW: https://azure.microsoft.com/es-es/services/sql-data-warehouse/
Doc. Producto: https://docs.microsoft.com/es-es/azure/sql-data-warehouse/
Visitas: 344
A partir del 30 de Enero, se encuentra disponible una herramienta de consulta totalmente web, que ofrece la posibilidad de ejecutar consultas en las bases de datos de SQL Azure y SQL Datawarehouse sin salir del Portal de Azure.
Este Editor de consultas de base de datos SQL se encuentra en Preview en el Portal de Azure.
Con este editor, se puede acceder y consultar bases de datos SQL Azure sin necesidad de conectarse desde una herramienta de cliente instalada en una PC o configurar reglas de firewall.
Paso 1
Como primer paso desde el portal de Azure debemos tener al menos una base de datos SQL Azure o SQL Datawarehouse en nuestra suscripción.
Una vez allí dentro del portal, y con nuestra base de datos seleccionada veremos en la parte superior un ícono “Tools”. Haciendo click sobre este, aparecerá una nueva ventana indicando la opción de conexión con Visual Studio (forma tradicional) y una nueva opción en preview de “Query Editor”

Luego de aceptar el modo de “preview”, se accede a la consola para ejecutar consultas.
Paso 2
Inicio de Sesión
Lo siguiente es realizar la conexión a la base de datos, ya sea mediante autenticación de SQL o bien a través de Azure Active Directory (AAD)
Para mas información de AAD :
Paso 3
Ejecución de Consultas
Una vez ya conectados, podemos ejecutar las consultas T-SQL en nuestro modelo de datos. Por el momento, solo podemos escribir nuevos querys, guardarlos o bien abrir un archivo .SQL ya existente.
Como primera experiencia, es una herramienta muy útil para rápidamente poder realizar consultas a las tablas o vista de sistema sin necesidad de abrir una conexión remota y configurar opciones de firewall que por defecto no están habilitadas.
Algo interesante para ver, es que si bien no es full-Intellisense a medidad que se va escribiendo el query quedan marcadas las sentencias que no están bien formadas, aumentando la velocidad de escritura evitando errores.
Ahora como contrapartida, y entiendo que al ser la primer versión preview, carece de muchísimos features a los que estamos acostumbrados desde el Management Studio (SSMS). Ya que únicamente podemos guardar el query o ejecutar uno previamente guardado. Los resultados no pueden ser exportados a ningún formato (si mediante copy/paste) y el resultado si es muy grande este se ve paginado.
En mi caso, lo primordial es carecer de forma visual rápida mínimamente una lista de tablas u objetos (tal como Object Explorer de SSMS) , ya que si no conocemos el modelo de tablas u objetos es un poco más difícil generar las consultas a los mismos. Y forzando a realizar consultas previas a las vistas de sistema para obtener los nombres y columnas.
Por suerte el grupo de producto proporcionó una casilla de email para poder enviar sugerencias y mejoras :