
Visitas: 1035
Nuevo Viejo Producto?
Durante el evento de Ignite de 2019, Microsoft anunció el cambio del servicio SQL Datawarehouse para pasar a llamarlo Synapse Analytics.
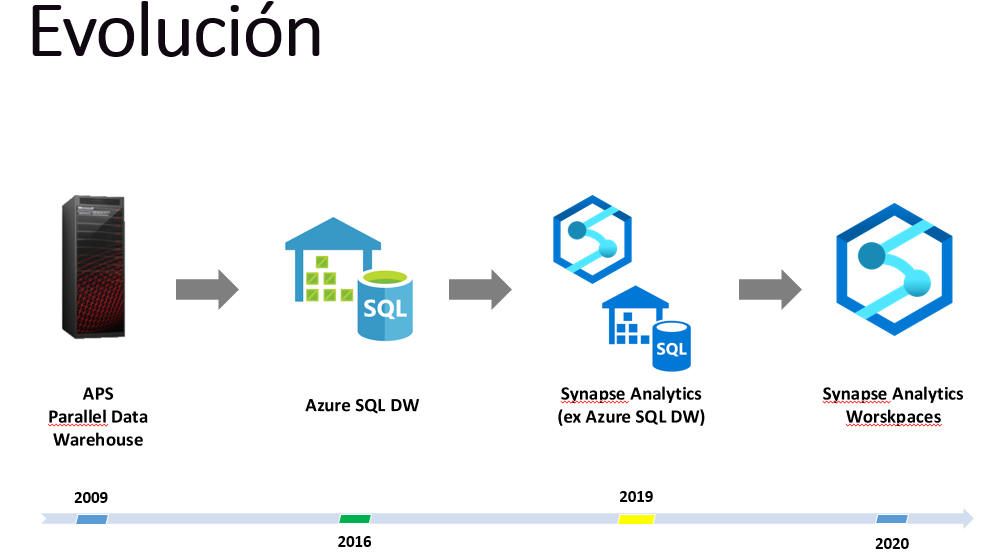
Mas allá del mero cambio de nombre, durante el anunció también dieron una muestra de una capacidad dentro de este servicio que llamaron Synapse Workspaces. Unificando así el mundo relacional con Big Data, Inteligencia Artificial y Power BI.
Ref: https://azure.microsoft.com/es-es/services/synapse-analytics/?WT.mc_id=DP-MVP-5003124
Rohan Kumar presentando en Ignite
Synapse Workspaces Componentes
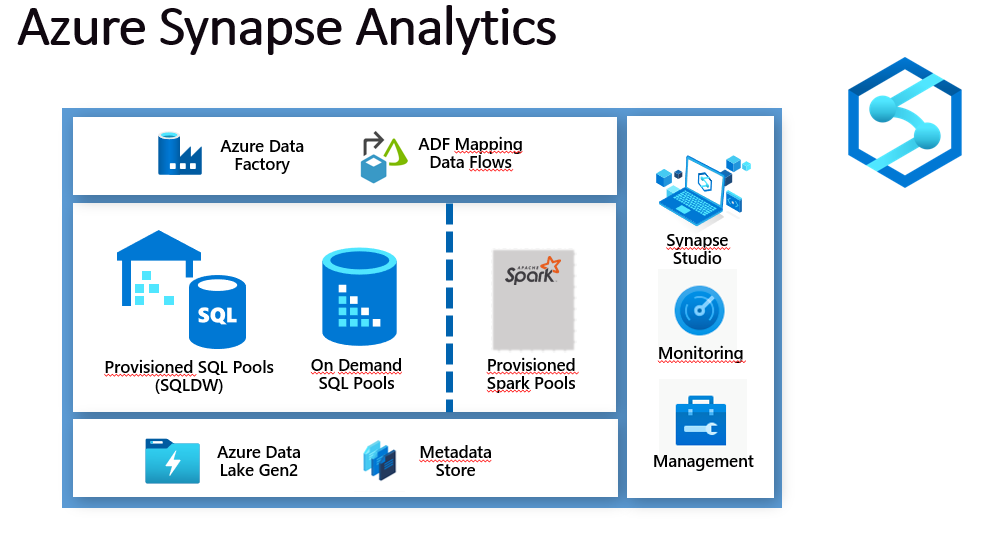
Ahora bien, dentro de esta plataforma Microsoft hizo un relanzamiento del ya conocido Azure SQL Datawarehouse, pero a la vez agregando nuevos componentes que llevan el análisis de datos más allá de un repositorio relacional para un Enterprise DataWarehouse.
Ahora con Synapse se pueden unificar los mundos Relacionales, No Relacionales, Big Data y Machine Learning en un solo lugar
Cómputo
En esta plataforma podemos aprovisionar dos tipos de cómputo, es decir crear un Pool de Recursos para SQL o bien de tipo Spark.
Un Pool de tipo SQL, nos permitirá ejecutar cargas de trabajo símil T-SQL con la opción de aprovisionar los recursos de capacidad (Provisioned – aka DWUs) o utilizar una versión Serverless (On Demand).
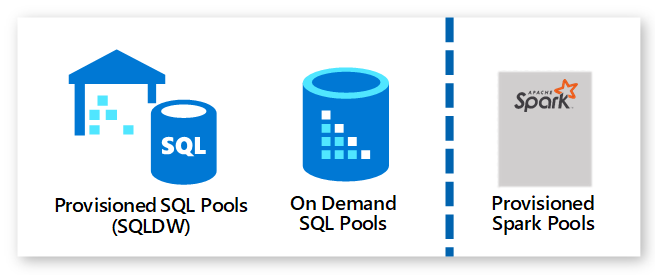
La novedad ocurre con los Spark Pools, que permiten ejecutar cargas de trabajo de tipo Analíticas y de Machine Learning con Notebooks de tipo Jupiter y múltiples lenguajes como Phyton, Scala, SparkSQL y .NET para Spark.
Estos últimos al momento de este post, solo pueden ser creados de forma aprovisionada.
Integración
Dentro la plataforma, contamos también con una sección de Integración, que se basa en Azure Data Factory y que permite realizar pipelines de integración (ELT/ETL) sin escribir código.

Almacenamiento
Como repositorio no relacional, Synapse se apoya en el ya bien establecido Azure Data Lake (Gen2) obteniendo así escalabilidad casi ilimitada, pero a la vez con el control que ofrece este componente en cuanto a seguridad y administración (ACLs, Keys, etc.)
Administración
Finalmente como punto de ingreso a esta plataforma, Microsoft nos ofrece Synapse Studio, una interfaz Web que une todos los componentes en un solo lugar y que permite tanto a Administradores como Desarrolladores y Usuarios gestionar todas las actividades.
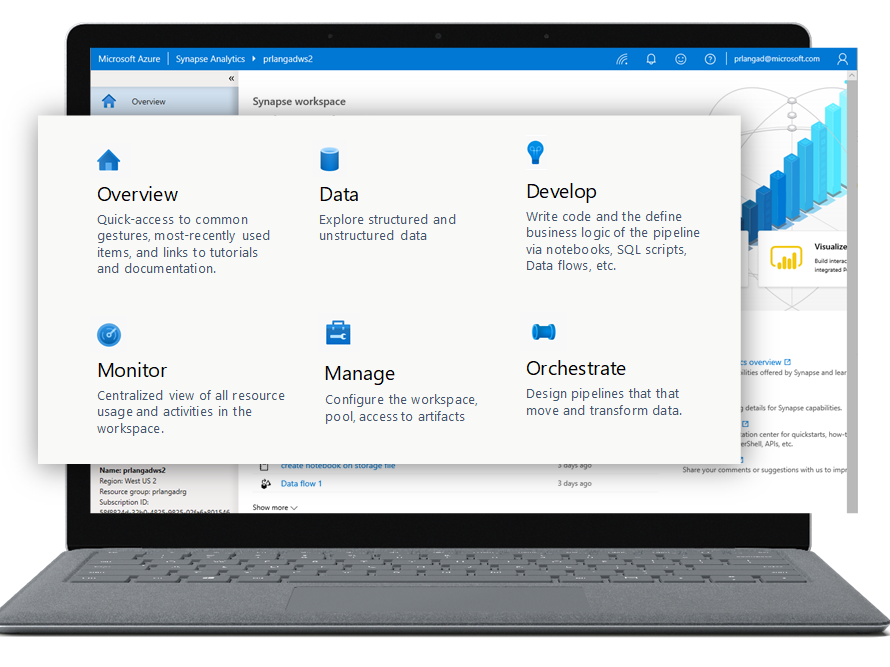
Y porque no… POWER BI
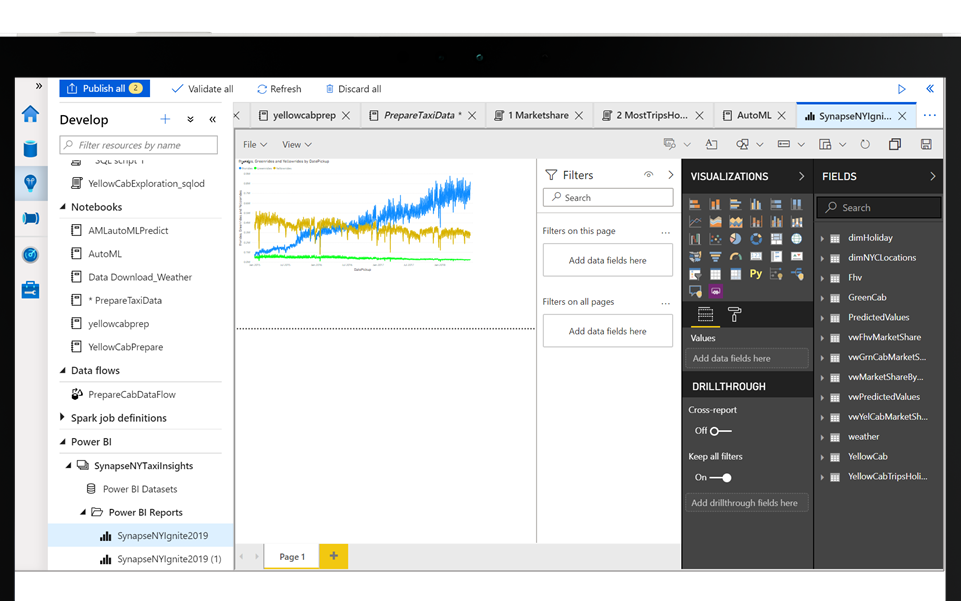
El mundo de analytics ya no solo pertenece a las areas de sistemas, sino cada vez mas a los usuarios del negocio, que a partir de Synapse podrán ver sus Workspaces de Power BI integrados en la misma consola aprovechando así los datos que otros sectores de la organización hayan podido preparar con los otros componentes de Synapse.
Recap
Microsoft pudo reunir en un solo lugar todas las capacidades de análisis de información y para toda una variedad de perfiles de usuarios.
Si bien hasta el momento se encuentra en Public Preview, este servicio promete muchísima capacidad y a la vez revalorizando el capital ya existente en las organizaciones.
En próximos post, analizaremos cada componente, costos y funcionalidades.


