
Visitas: 1004
Para todo hay una primera vez, y esta fue el turno de un nodo caído en una solución de Always On Availability Groups en un Failover Cluster de 5 nodos distribuidos geográficamente.
La configuración de cada nodo se compone:
- Virtual Machine – VMWare ESX Hypervisor
- 2 Socket – 2 Processors
- Windows Server 2012 R2 RTM
- SQL Server 2016 SP1 Build 13.0.4001.0
- 1 Availability Group sobre 2 nodos
- 1 Availability Group sobre 5 Nodos
Arquitectura
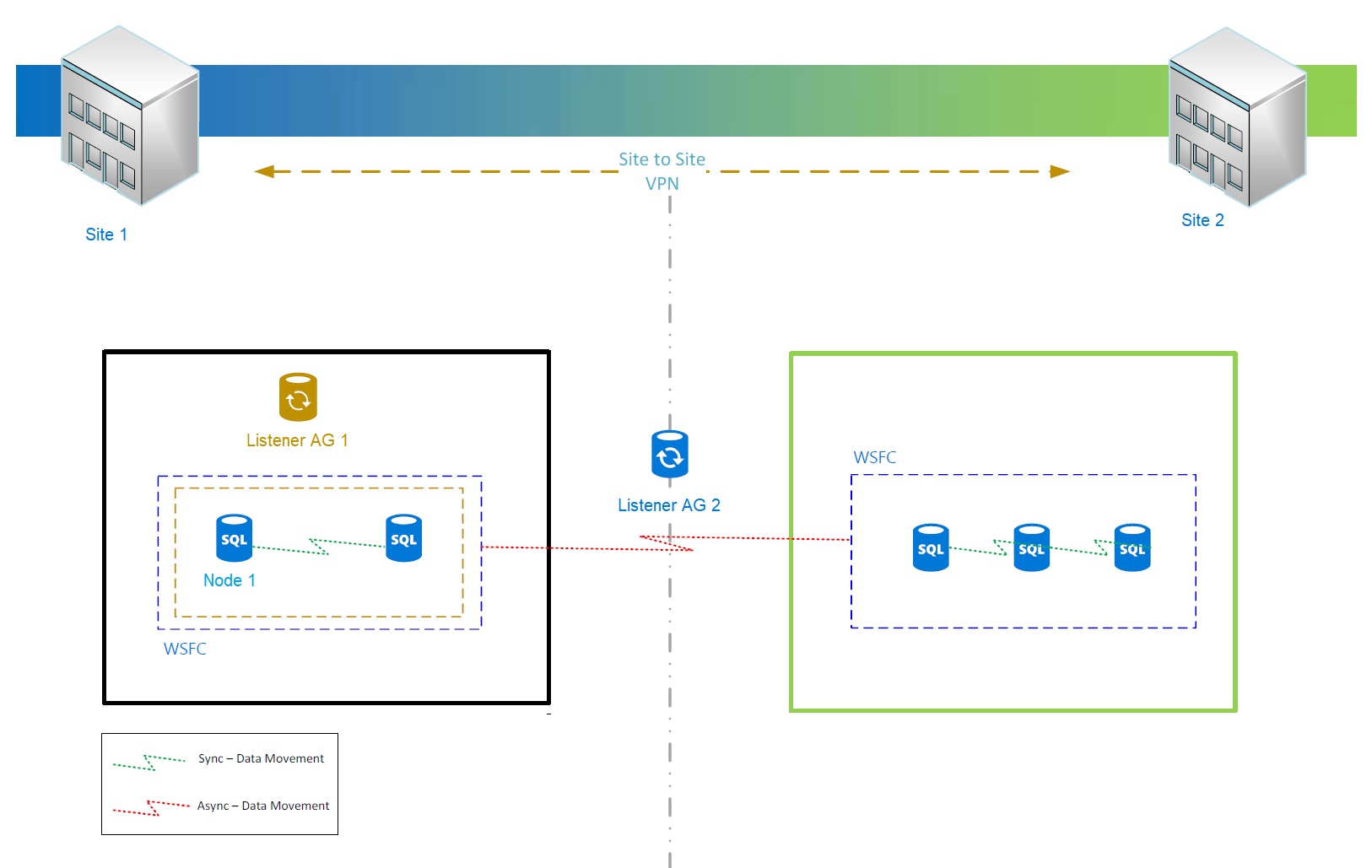
Luego de un reinicio inesperado sobre el nodo secundario del AG1, las bases de datos quedaron en un estado de Recovery Pending.
El nodo 2 de la solución quedó permanente en estado de Offline dentro del Failover Cluster Manager.
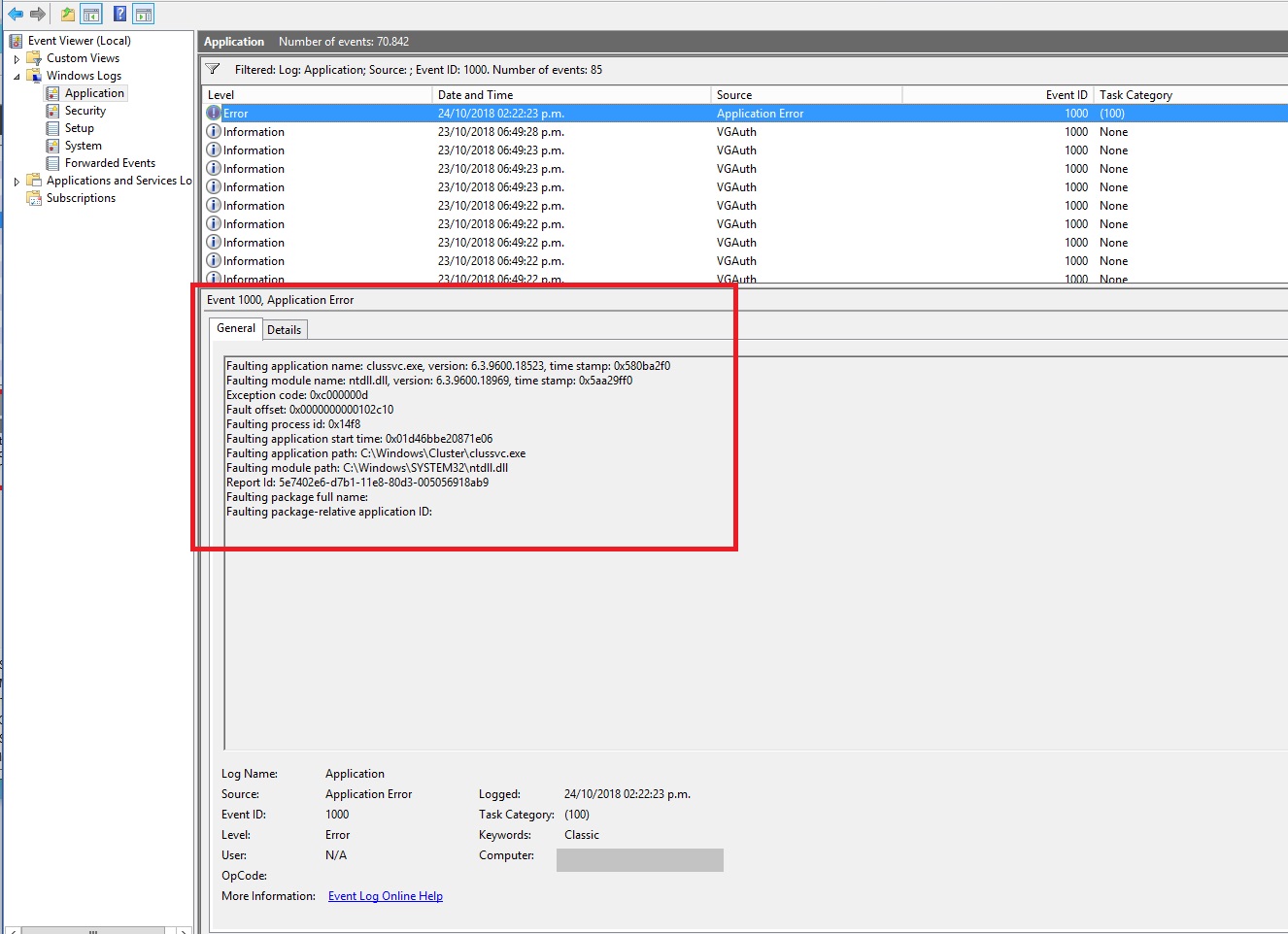
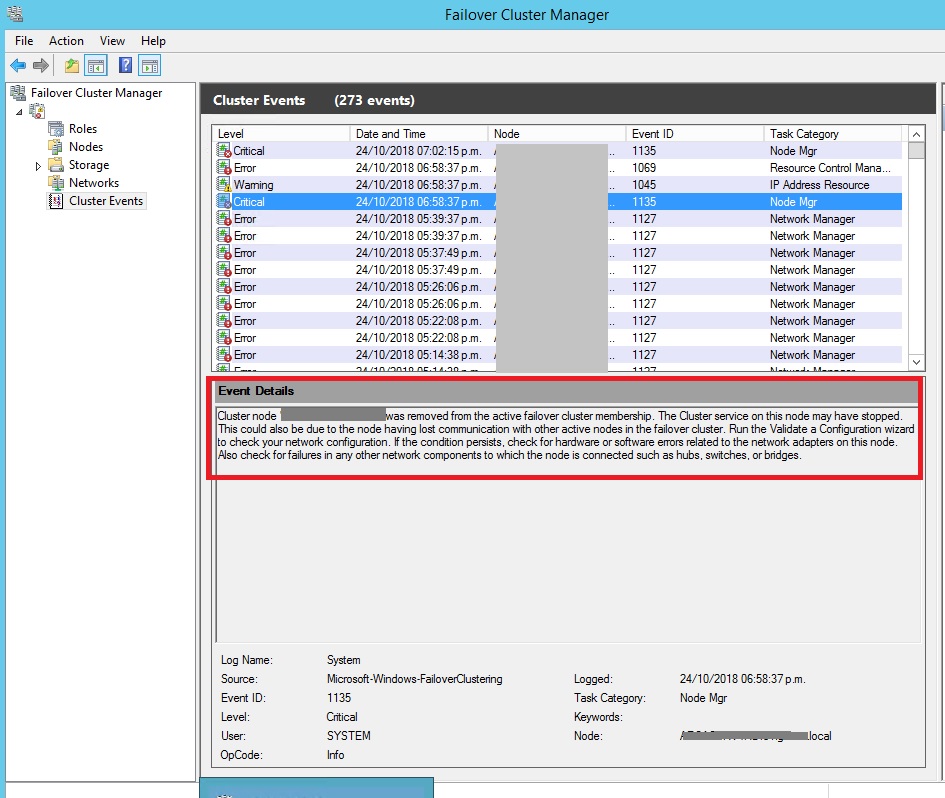
Los eventos que aparecieron en el Event Viewer y Failover Cluster Manager:
Event ID 1000
Event ID 1135
Para resolver esta situación, oficialmente Microsoft tiene un KB que repara esta situación. El mismo debe ser aplicado a nivel de Windows:
Una vez aplicado el KB en todos los nodos y reinicio correspondiente, automáticamente el servicio de Cluster inicia correctamente en todos los nodos y la solución de Always On vuelve a sincronizar a los nodos..
Moraleja de la historia, es importante tener un plan de actualización de Service Packs y KBs ya que se pueden evitar situaciones como ésta en Producción y evitar downtimes.
